حل تشریحی سوالات شناسایی الگو - یادگیری ماشین - کنکور دکتری مهندسی کامپیوتر 1402
سوالات شناسایی الگو - یادگیری ماشین
25 سوالنزدیکترین فاصله نقطه z از ابر صفحه کدام است؟
در دسته بندی یک مسئله M دسته ای به کمک روش بیزین، کدام رابطه در مورد احتمال خطای دسته بندی دسته بند بهینه یا همان صادق است؟
در ساخت یک جنگل تصادفی هر درخت را بر اساس نمونه گیری Bootstrap از داده های آموزشی میسازیم. اگر n تعداد کل نمونه های آموزشی و d تعداد ویژگی باشد، به طور متوسط هر درخت بر اساس چه تعداد نمونه آموزشی ساخته می شود؟
فرض کنید در یک مسئله دسته بندی داده های دارای دو ویژگی و هستند که هر کدام مقادیر یا را می گیرند و برچسب طبقه هم مقدار صفر یا یک را میگیرد. سه فرضیه به صورت زیر تعریف شده اند:
کدام یک از فرضیه های فوق را میتوان از طریق یک پرسپترون با گرفتن وزنهای مناسب پیاده سازی کرد?
و
در دسته بندی یک مسئله دو دسته ای با داده های آموزش به شرح جدول زیر دو دسته بند Bayes و Naive Bayes داده آزمون (180 = Weight = 80, Height) را در کدام دسته دسته بندی می کنند؟
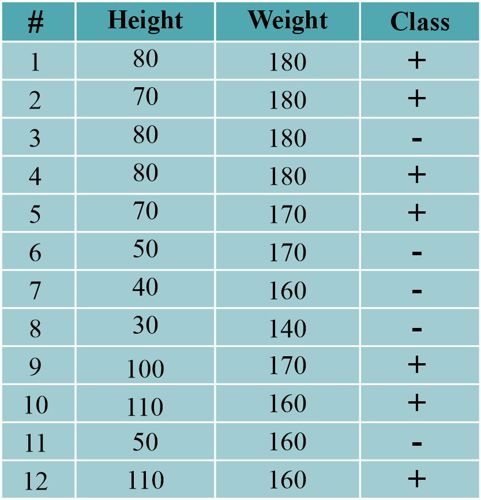
هر دو مثبت
هر دو منفی
نمودار زیر در رابطه با تعداد تکرارهای مورد نیاز برای دستیابی به کمینه خطا با استفاده از الگوریتم نزول در امتداد گرادیان تصادفی (SGD) را در نظر بگیرید گزینه درست کدام است؟
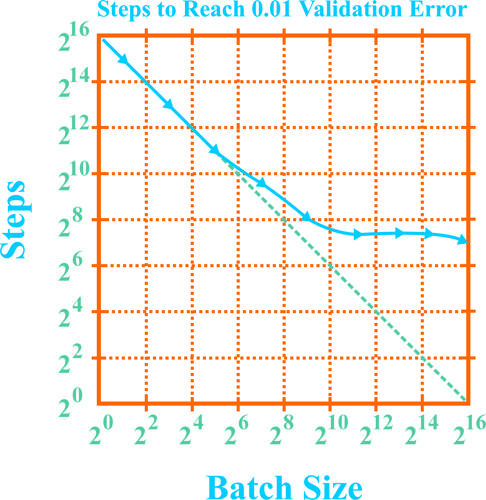
اندازه دسته یا Batch-sizeهای بزرگتر واریانس را در تخمین گرادیان در الگوریتم SGD افزایش می دهند.
با تعداد بروزرسانی یکسان اندازه دسته های بزرگتر نسبت به اندازه دسته های کوچکتر سریع تر همگرا می شوند.
بر اساس این شکل اندازه دسته های نسبتا کوچک هم میتواند همگرایی سریع را تضمین نماید.
همه موارد
مسئله دسته بندی دودویی زیر را در نظر بگیرد. فرض کنید مجموعه آموزش حاوی نمونه های متفاوتی از الگوی A و B باشند. آیا یک شبکه عصبی حاوی یک لایه کانولوشنی یک بعدی با یک تابع فعال سازی (Activation function) خطی که به دنبال آن لایه خطی با خروجی لجستیک قرار دارد میتواند به طور کامل همه نمونه های آموزش را دسته بندی نماید؟

بله فقط باید خروجی لجستیک تغییر یابد.
خیر اما افزودن یک لایه کانولوشنی یک بعدی دیگر میتواند مسئله را حل کند.
بله لایه کانولوشنی به خوبی میتواند شرایط جداپذیری را در این الگوها قابل شناسایی نماید.
خیر این مسئله ذاتا قابل جدایی پذیری خطی نیست و نیاز است شبکه پیچیده تری جایگزین گردد.
در یک مسئله دو دسته ای بر روی داده های یک بعدی، اگر تابع توزیع دسته های و به ترتیب توابع گوسی و باشد مقدار آستانه که مقدار risk Average را کمینه می کند کدام است؟ را ریسک آن در نظر بگیرید که داده ای از دسته k در دسته i دسته بندی نماییم همچنین فرض کنید )
فرض کنید نمونههایی باشند که بهصورت از تابع انتخاب شده باشند. تخمین MLE برای پارامتر کدام است؟
زنجیره مارکوف با ماتریس گذار زیر را در نظر بگیرید امید ریاضی تعداد روزهای ماندن در وضعیت Sunny با شروع از وضعیت Sunny چند است؟
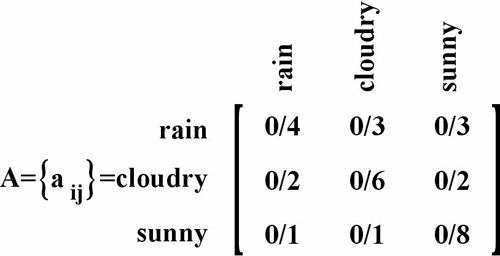
1/25
2/25
4
5
در مبحث کاهش ابعاد و انتخاب ویژگیها کدام یک از گزاره های زیر نادرست است؟
روش آنالیز تشخیص خطی (LDA) یک ترکیب خطی از ویژگیها برای تفکیک بهتر فضای داده به دست می دهد.
تبدیل موجک روشی برای انتقال فضای داده اصلی به فضای جدید با استفاده از ترکیب توابع موجک پایه دلخواه است.
شبکه های عصبی خود کد گذار روشی برای کاهش بعد داده به شمار می آیند که قادرند یک بردار ویژگی غنی از اطلاعات را به دست دهند.
الگوریتم PCA و ICA فضای داده را به یک فضای جدید با همان تعداد بعد یا کمتر انتقال می دهند به گونه ای که فاصله بین هر دو نمونه داده با فاصله در فضای قبلی یکسان باقی می ماند.
در نگاشت داده از فضای داده به فضای با بعد بالاتر به صورت شکل تابع هسته متناظر با ضرب داخلی داده ها در فضای هسته به کدام صورت است اگر تابع به صورت رابطه زیر باشد؟
یک تابع PDF به صورت زیر داده شده است:
کدام است؟
اگر S ماتریس کواریانس یک مجموعه داده و میانگین آن باشد و داشته باشیم (ستون Q بردارهای ویژه و قطر D مقادیر ویژه S هستند.) در کدام حالت داده ها ناهمبسته (uncorrelated) خواهند بود؟
کدام مورد نتیجه میان گیری خروجی تعدادی درخت تصمیم است؟
کاهش بایاس
افزایش بایاس
کاهش واریانس
افزایش واریانس
در هنگام انتخاب یک زیر مجموعه از ویژگیها تلاش میکنیم که ویژگیهای نامناسب را تشخیص دهیم و آنها را حذف کنیم کدام مورد دلیل حذف ویژگی ها نیست؟
کاهش بایاس مدل
کاهش واریانس مدل
افزایش تفسیر پذیری مدل
افزایش سرعت پیش بینی روی نمونه های آزمون
یک دسته بند Hard margin linear SVM که بر روی یک مجموعه داده تایی آموزش دیده است با ۲ = k بردار پشتیبان (Support vector) را در نظر بگیرید. اگر یک داده برچسب دار جدید به مجموعه داده موجود اضافه کنیم حداکثر تعداد Support vectorها چند خواهد بود؟
k
n
n+1
k+1
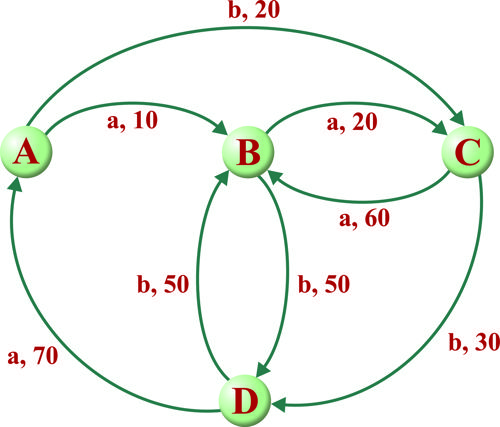
قصد داریم تا به روش یادگیری تقویتی سیستمی با چهار حالت (A,B,C,D) را که در هر حالت تنها دو کنش a و b امکان پذیر است آموزش دهیم شکل زیر امکان انتقال بین حالات و همچنین پاداش دریافتی به ازای هر کنش در هر حالت را نشان میدهد. در صورتی که از الگوریتم Q-Learning برای آموزش استفاده نماییم و باشد، مقادیر تابع Q چه خواهد بود در صورتی که از حالت A شروع کرده و کنشهای را به ترتیب از چپ به راست انجام دهیم؟
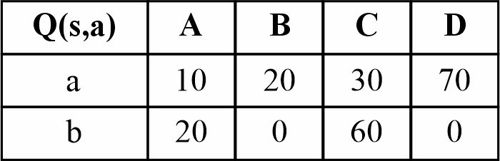
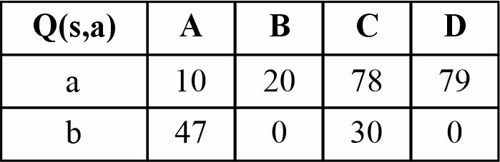
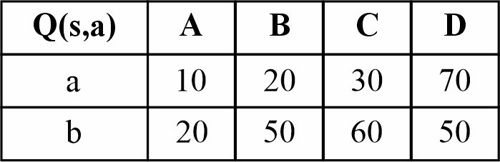
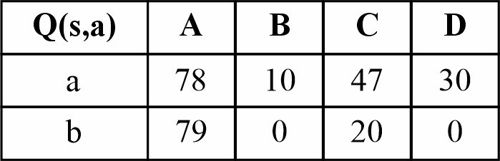
اگر در دسته بندی مسئله ای با ویژگیهای عددی به کمک درخت تصمیم یک ویژگی خاص مانند را نرمال کنیم تأثیر آن چگونه است؟
ویژگی در ارتفاع بالاتری از درخت قرار می گیرد.
ویژگی در ارتفاع پایینترین از درخت قرار می گیرد.
هیچ تأثیری بر شکل درخت و نتیجه دسته بندی ندارد.
با نرمال سازی ویژگی نمیتوان در مورد شکل درخت و نتیجه دسته بندی نظر قطعی داد.
در رگرسیون خطی سه داده و در فضای دوبعدی، با مقدار بهصورت زیر استفاده شده است. در صورتی که خطای رگرسیون یا همان بهصورت اعداد درج شده بر روی کانتورهای بیضی شکل و جریمه ناشی از Regularization یا همان بهصورت اعداد درج شده بر روی کانتورهای مربع شکل رسم شده در شکل زیر باشد:
کدامیک از شکلهای زیر نشاندهنده نتیجه رگرسیون است؟
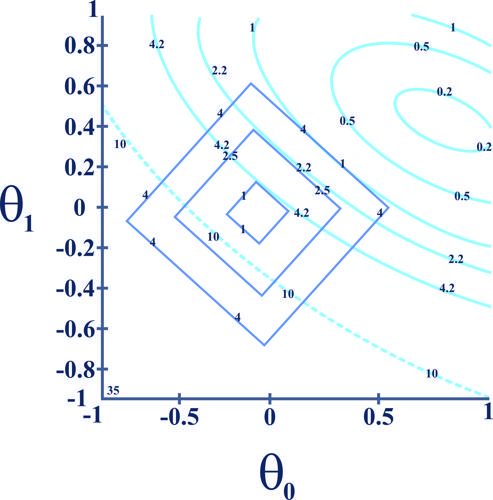
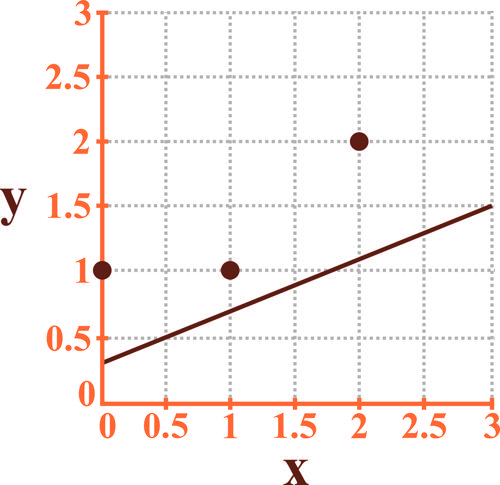
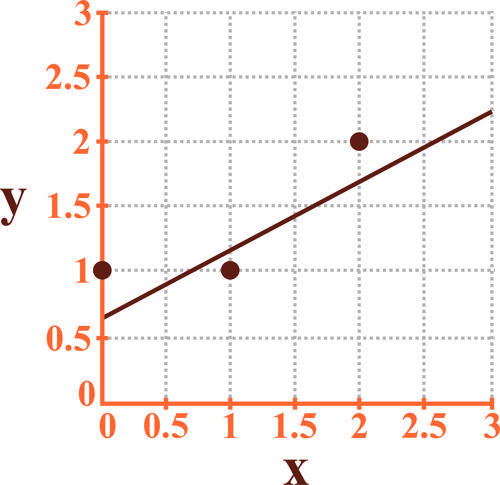
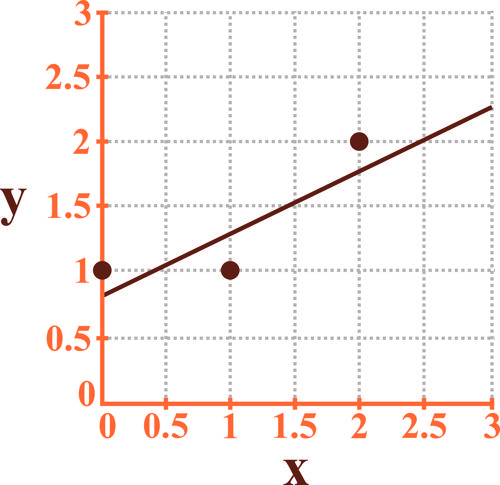
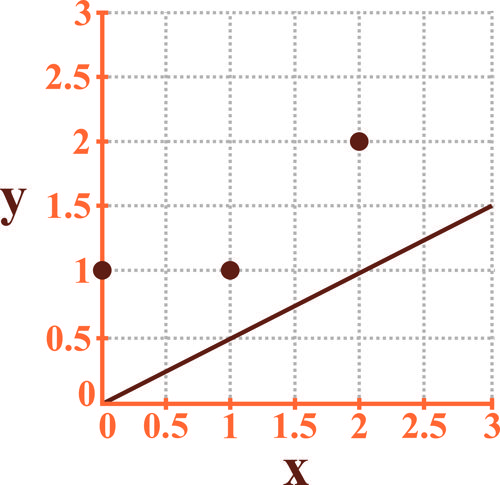
اگر بخواهیم مسئله دسته بندی دو دسته ای شکل زیر را به کمک مدل Regularized logistic regression بیان شده زیر حل کنیم مرز تصمیم رسم شده در شکل برای کدام حالت می تواند درست باشد؟
کدام یک از دسته بندهای زیر نسبت به چرخش داده ها (Rotation) بسیار حساس است؟ (فرض کنید همه ویژگی ها
عددی هستند.)
SVM
رگرسیون لجستیک
درخت تصمیم
نزدیک ترین همسایه
اگر بخواهیم روش رگرسیون لجستیک را برای یک مسئله K دسته ای بسط دهیم و اینگونه عمل کنیم که دسته را به عنوان Pivot انتخاب نماییم و برای هر دسته به صورت جداگانه رگرسیون لجستیک را نسبت به دسته Pivot انجام دهیم را به صورت زیر محاسبه نماییم آنگاه کدام رابطه برای درست است؟
..............
در یک دسته بند که همیشه با احتمال ۰٫۷ = P برچسب مثبت به داده ها انتساب می دهد. مقدار کدام است؟
AUC (Area under ROC curve)
0/7
0/5
0/3
0/15
در محاسبه حد بالای Sample complexity به کمک روشهای مبتنی بر یادگیری PAC، در صورتی که Learner هیچ فرضی در مورد اینکه target concept به کمک فضای فرضیه H قابل نمایش است نداشته باشد. و فقط فرضیه با کمترین خطای آموزش را برگرداند از کدام رابطه می توان بهره برد؟
با توجه به اینکه Learner نمی تواند یک فرضیه سازگار (Consistent) بیاید امکان محاسبه حد بالای Sample complexity وجود ندارد.