حل تشریحی سوالات شناسایی الگو - یادگیری ماشین - کنکور دکتری مهندسی کامپیوتر 1403
سوالات شناسایی الگو - یادگیری ماشین
25 سوالیک شبکه عصبی پرسگترونی، با دو نهرون در لایه ورودی، 3 نرون در لایه پنهان و یک نرون در لایه خروجی داریم. کدامیک از توابع فعالیت زیر (برای نرونهای لایه پنهان) فضای دوبعدی ورودی را به نقاط داخلی مکعبی به اضلاع واحد نگاشت میکند؟
پله واحد
تانژانت هیپربولیک
ReLu
سیگموئید
در یک مسئله طبقهبندی دو کلاسه با روش C-SVM در صورت افزایش C، کدام مورد در رابطه با عرض حاشیه (margin) درست است؟
تغییر نمیکند.
افزایش مییابد.
کاهش مییابد.
در حالت کلی نمیتوان اظهار نظر کرد.
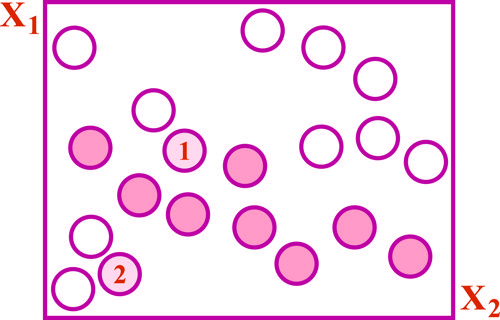
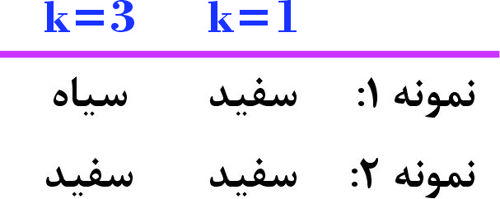
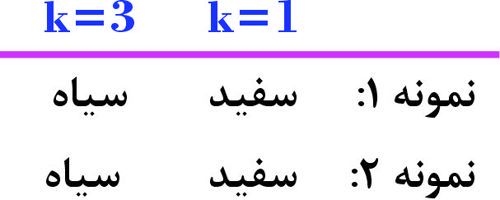
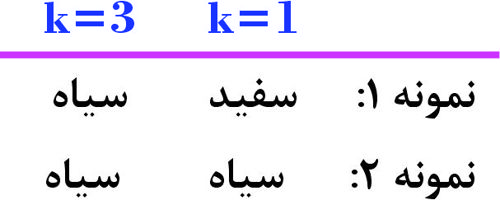
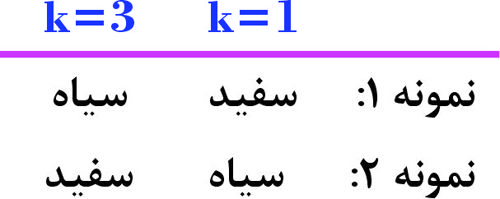
شکل زیر، طبقهبندی دادهها با دو کلاس سفید و سیاه را نشان میدهد. دو نمونه داده خطچین 1 و 2، هنوز طبقهبندی نشدهاند. اگر از روش K_NN، با مقادیر K=1، K=3 بدون تابع وزندهی استفاده کنیم، کلاسهای اختصاص یافته به این دو نمونه، کدام است؟
برای بردار تصادفی x با میانگین صفر، در مورد تعداد مقادیر ویژه غیرصفر ماتریس همبستگی و ماتریس کوواریانس آنها کدام مورد درست است؟
برابر است.
در حالت کلی نمیتوان اظهار نظر کرد.
تعداد مربوط به ماتریس همبستگی بیشتر است.
تعداد مربوط به ماتریس کوواریانس بیشتر است.
ضریب همبستگی بین دو ویژگی i و j با استفاده از کواریانس آنها، با رابطه تعریف میشود که و انحراف معیار دو ویژگی است. کدام مورد در خصوص ضریب همبستگی درست است؟
همواره نامنفی است.
میتواند مثبت یا منفی باشد.
هر عدد حقیقی میتواند باشد.
اگر ضریب همبستگی این دو ویژگی صفر باشد، ویژگیها مستقل از هم هستند.
اگر فاصله ماهالانوبیس دو نقطه برابر و فاصله اقلیدسی همان نقاط باشد، کدام مورد همواره درست است؟
در حالت کلی، نمیتوان اظهار نظر کرد.
برای طبقهبندی یک مسئله 2 کلاسه، از یک پرسپترون (با بردار وزن w و بایاس با تابع فعالیت زیر، استفاده شده است. در صورتی که بردار وزن اولیه w را صفر درنظر بگیریم، پس از وارد کردن فقط یک داده به پرسپترون، کدام یک از شروط زیر باید برقرار باشد تا کلیه وزنهای w صفر باقی بمانند؟
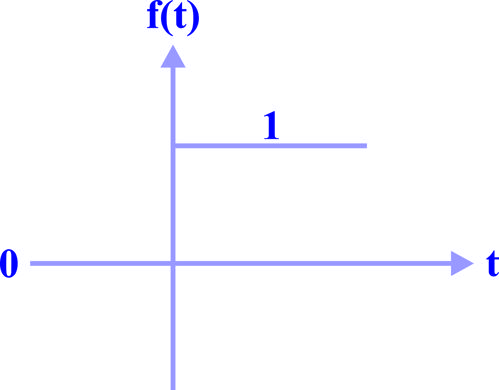
و ورودی متعلق به کلاس یک باشد.
و ورودی متعلق به کلاس صفر باشد.
و ورودی متعلق به کلاس صفر باشد.
و ورودی متعلق به کلاس یک باشد.
در یک مسئله دو کلاسه و دوبعدی، مرز تصمیم برای یک طبقهبندی از نوع درخت تصمیم، چه شکلی میتواند داشته باشد؟
تعدادی هذلولی
تعدادی خط مایل
تعداد خطوط افقی و عمودی
تعدادی دایره یا بیضی
در طبقهبندی کننده بیز دوکلاسه با دو ویژگی، مرز تصمیم کدامیک از حالتهای زیر نمیتواند باشد؟
دو خط متقاطع
هذلوله
بیضی
سهمی
در یک مسئله طبقهبندی دو کلاسه، نتایج زیر بهسوی دادههای تست بهدست آمده است. x چه مقداری نمیتواند باشد؟
20= تعداد دادهها در کلاس منفی
صفر
1
2
3
و را دو کلاس در نظر بگیرید که توابع توزیع بردار ویژگی x در دو کلاس، بهصورت و است. اگر، و ، آنگاه رابطه مرز تصمیم دو کلاس توسط Bayesian classifier کدام است؟ (توجه: در گزینهها، K را تابعی از ها در نظر بگیرید.)e
در یک نرون عصبی از نوع پرسپترون، از تابع فعالیت سیگموئید (تابع زیر) استفاده شده است. اگر خروجی نرون برای یک ورودی خاص شده باشد، مقدار مشتق تابع سیگموئید در آن لحظه، چه مقدار است؟
کدام روش زیر، نمیتواند به خطای آموزش صفر برای هر دادگان جداییپذیر خطی برسد؟
پرسگترون
درخت تصمیم
k-NN با k=1
Hard-margin SVM
در یک پرسپترون که از تابع فعالیت سیگموئید استفاده میکند، کدام مورد درست است؟
فقط امکان انفجار گرادیان وجود دارد.
فقط امکان محوشدگی گرادیان وجود دارد.
محوشدگی گرادیان و انفجار گرادیان برای آن، ممکن نیست.
ممکن است هم دچار محوشدگی گرادیان و هم انفجار گرادیان بشود.
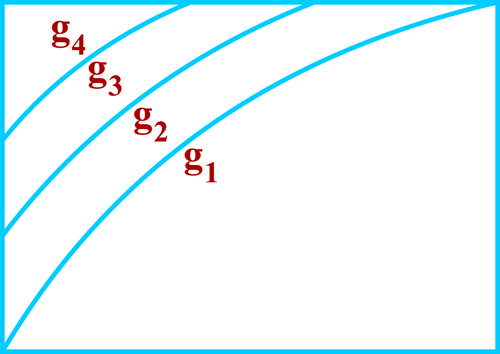
از بین طبقهبندیهای نمودار ROC شکل زیر، کدامیک به تصمیم تصادفی نزدیکتر است؟ ( مربوط به ضلع بالا و سمت چپ مربع است).
در صورتی که بخواهیم یک تابع خطای محدب f(x) را با روش stochastic gradient descent به حداقل برسانیم، با فرض شروع از یک نقطه اختیاری، کدام مورد زیر درباره ضریب یادگیری در مرحله t (یعنی )، رسیدن به پاسخ بهینه سراسری را تضمین میکند؟
اگر در هر مرحله، باشد.
اگر در هر مرحله، و باشد.
اگر در هر مرحله، بهصورت تغییر کند.
اگر در هر مرحله، بهصورت تغییر کند.
در یک دسته داده جداییپذیر خطی دوکلاسه، یک طبقهبند Hard SVM آموزش دادهایم، اگر داده جدیدی به دادگان آموزشی اضافه شود، به قسمتی که در داخل حاشیه (margin) قرار گرفته و دادگان کماکان جداییپذیر خطی باقی بمانند، در صورت آموزشی مجدد سیستم با دادگان جدید، کدام مورد در خصوص عرض حاشیه، درست است؟
تغییر نمیکند.
کوچکتر از قبل میشود.
بزرگتر از قبل میشود.
در حالت کلی، نمیتوان اظهارنظر کرد.
در یک طبقهبندی دوکلاسی تک بُعدی که نسبت احتمال پیشین دو کلاس است، یک ویژگی داریم که تابع چگالی احتمال آن در دو کلاس، بهصورت زیر داده شده است. مرز طبقهبند بیز کدام است؟
؟؟؟
صفر
1
4
در یک مسئله k-nn با مقدار k=1، در صورتی که تعداد دادهها به سمت بینهایت میل کند، تضمین میشود که خطای سیستم، از چه حدی نسبت به خطای بیز، فراتر نمیرود؟
ربع
نصف
دو برابر
چهار برابر
در یک مسئله طبقهبندی دوکلاسی با سه ویژگی، بردار میانگین و ماتریس کوواریانس دو کلاس، بهصورت زیر داده شده است. میخواهیم با معیار فیشر (نسبت پراکندگی بین کلاس به پراکندگی درون کلاسی) از بین سه ویژگی، ویژگی بهتر را انتخاب کنیم. کدام ویژگی بهتر است؟
اول
دوم
سوم
تمایزی بین سه ویژگی نیست.
در فضای دوبُعدی ، دو داده از دو کلاس بهصورت زیر داریم (دادههای معروف به XOR)، با تبدیل ، این چهار داده را به فضای دوبُعدی میبریم. با کدام تبدیل، در فضای دادهها جداییپذیر خطی خواهند بود؟
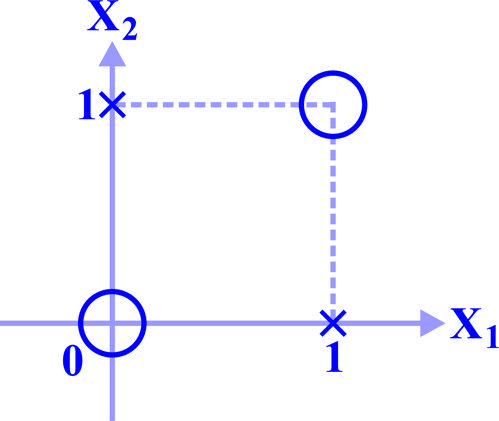
XOR | ||
|---|---|---|
0 | 0 | 0 |
1 | 1 | 0 |
1 | 0 | 1 |
0 | 1 | 1 |
از یک متغیر تصادفی گوسی با متوسط مجهول و واریانس معلوم، N مشاهده را داریم: ، با روش Maximum Likelihood ، مقدار متوسط را تخمین زده و آن را مینامیم. اگر به N داده فوق، یک داده دیگر که از همان توزیع تولید شده اضافه کنیم و مجددا با روش ML، متوسط را تخمین زده و بنامیم، کدام رابطه، همواره درست است؟
در حالت کلی، نمیتوان در مورد برابری و اظهار نظر کنیم.
کدام مورد درباره خوشهبندی k-means، درست است؟
یک روش با نظارت است.
با افزایش تعداد خوشهها، هرگز نمیتوان مقدار بهینه تابع هزینه را افزایش داد.
مقادیر مراکز نهایی خوشهها، همواره مستقل از مقادیر مراکز اولیه خوشهها هستند.
مستقل از مقادیر تنظیمات اولیه، این روش همواره به یک جواب منحصر به فرد میرسد.
کدام مورد درباره روش bagging، درست است؟
در این روش، از نمونهبرداری تصادفی با جایگذاری استفاده میشود.
هدف اصلی آن کاهش با یاس الگوریتم یادگیرنده است.
تنها زمانی به کارای بالاتر از یادگیرنده (learner) اولیه میرسد که دقت همگی آنها، کمتر از 0/5 باشد.
در صورت استفاده از آن برای Logistic regression، پاسخ خوبی بهدست نمیآید، زیرا همه یادگیرندهها (learners)، دقیقا به یک مرز تصمیم میرسند.
در مقایسه دو طبقهبند نزدیکترین همسایگی 1-NN با 3-NN، کدام مورد در رابطه با 1-NN درست است؟
دارای واریانس و بایاس کمتری است.
دارای واریانس و بایاس بیشتری است.
دارای واریانس کمتر و بایاس بیشتری است.
دارای واریانس بیشتر و بایاس کمتری است.