حل تشریحی سوالات شناسایی الگو - یادگیری ماشین - کنکور دکتری مهندسی کامپیوتر 1404
سوالات شناسایی الگو - یادگیری ماشین
25 سوالبرای یک طبقه بند Hard-SVM دو کلاسه، 4 عدد داده آموزشی متعادل (balanced) از هر دو کلاس، که به طور خطی جدایی پذیر هستند موجود است. کدام یک از مقادیر زیر نمی تواند تعداد بردارهای پشتیبان آن پس از اتمام فاز آموزش باشد؟
2
1
4
3
در آموزش پرسپترون که داده ها یکی یکی در هر مرحله به آن داده می شوند و ضریب یادگیری با افزایش مراحل i با فرمول کاهش می یابد، کدام مورد در خصوص تاثیر تغییرات ضریب یادیگیری با i درست است؟
اصلاً ارتباطی بر تأثیر داده ها ندارد.
تأثیر داده های ابتدایی، کمتر از داده های انتهایی می شود.
تأثیر داده های انتهایی، کمتر از داده های ابتدایی می شود.
تأثیر داده های انتهایی و داده های ابتدایی، تقریبأ برابر می شود.
کدام مورد زیر، می تواند ماتریس کواریانس یک مجموعه داده باشد؟
؟؟؟؟
؟؟؟؟
؟؟؟؟
؟؟؟؟
فرض کنید می خواهیم سیستمی مبتنی بر یادگیری برای تبدیل صوت به متن ایجاد کنیم که برای هر صوت، متن مرتبط با آن را نیز داریم. داده های ما صوت هایی به زبان فارسی هستند، ولی لهجه های مختلفی در آنها وجود دارد که در مجموعه آموزشی، برچسبی برای لهجه ها وجود ندارد. اگر بخواهیم از تأثیر لهجه ها در یادگیری استفاده شود، فرایند یادگیری در این مسئله باید چگونه باشد؟
ابتدا مبتنی بر دسته بندی و سپس مبتنی بر خوشه بندی
ابتدا مبتنی بر خوشه بندی و سپس بر دسته بندی
تنها مبتنی بر دسته بندی
تنها مبتنی بر خوشه بندی
در کدام یک از طبقه بندی های زیر، برای فاز تست لازم است همه داده های آموزشی یا بخشی از آنها استفاده شود؟
درخت تصمیم
شبکه عصبی MLP
Hard-SVM
K-nn
در الگوریتم C-SVM ، مسئله بهینه سازی مقید زیر را داریم:
تابع لاگرانژ به صورت زیر نوشته شده است:
اگر برای C=5 مسئله حل شده باشد و برای داده داشته باشیم ، آنگاه کدام گزاره نادرست است؟
و این داده درست طبقه بندی شده است.
و این داده درست طبقه بندی شده است.
و این داده روی مارجین (حاشیه) قرار دارد.
و این داده روی مارجین (حاشیه) قرار دارد.
در فضای دوبعدی، 10 داده داریم که می خواهیم با روش K-means با معیار اقلیدسی یک خوشه بندی دو کلاس انجام دهیم. برای شروع کار، دو نقطه دلخواه را به عنوان مرکز دو خوشه قرار می دهیم و الگوریتم را اجرا می کنیم و داده ها به جز دو نقطه اولیه، به ترتیب شماره اندیس به الگوریتم وارد می شود. نتیجه نهایی خوشه بندی با دو نقطه اولیه و با نتیجه خوشه بندی با کدام دو نقطه اولیه در گزینه های زیر، یکسان نیست؟
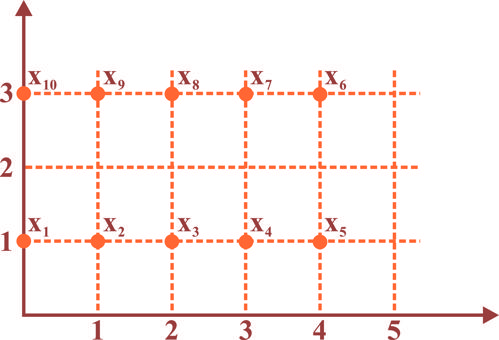
و
و
و
و
برای ارزیابب یک تخمین زننده، با یاس و واریانس آن را محاسبه می کنند. کدام تخمین زننده بهتر است؟
بایاس آن کم و واریانس آن زیاد باشد.
بایاس و واریانس آن کم باشد.
بایاس آن زیاد و واریانس آن کم باشد.
بایاس و واریانس آن زیاد باشد.
در یک طبقه بندی دو کلاسی با دو ویژگی، از کلاس 1 به تعداد 100 داده آموزشی داریم که در ناحیه A در شکل زیر و از کلاس 2 به تعداد 100 داده آموزشی داریم که در ناحیه B در شکل زیر هر دو به صورت تصادفی قرار دارند. می خواهیم به داده ای که در شکل با نقطه M مشخص شده است، با طبقه KNN با K=1 و فاصله اقلیدسی یک برچسب بدهیم. کدام مورد درست است؟
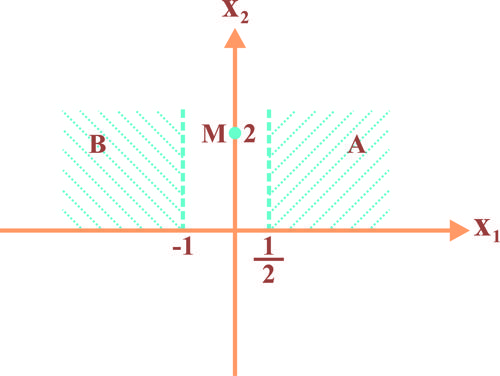
بدون دیدن داده های آموزش، نمی توان برچسب را تعیین کرد.
همواره احتمال تعلق داده به هر دو کلاس، برابر است.
برچسب این داده، کلاس 1 است.
برچسب این داده، کلاس 2 است.
اگر در یک مسئله طبقه بندی دو کلاسی در فضای ویژگی دو بعدی، ماتریس کوواریانس و میانگین کلاس ها مقادیر زیر باشند:
آنگاه نقاطی که فاصله ماهالانوبیس ثابت 10 را از میانگین کلاس خود دارند، حداکثر مقدار فاصله اقلیدسی آنها از همان میانگین، چقدر خواهد بود؟
30
40
50
60
برای طبقه بندی داده های XOR در فضای دوبعدی، کدام یک از طبقه بندهای زیر مناسب هستند؟
a) طبقه بند درخت تصمیم
(b طبقه بند Hard SVM
(c یک نرون عصبی مصنوعی پرسپترون
(d طبقه بند شبکه عصبی MLP
a و b
b و c
a و d
c و d
اگر برای متغیر تصادفی x تابع چگالی احتمال داده نشده باشد، ولی میانگین و واریانس آن معلوم باشد، با روش حداکثر آنتروپی، کدام یک از توابع چگالی احتمال زیر به دست می آید؟
تابع ؟؟؟؟
تابع اگر ????
تابع
کدام مورد، در خصوص ماشین های بردار پشتیبان SVM درست است؟
در یک مسئله جدایی ناپذیر خطی با افزایش C در روش C-SVM، حاشیه (margin) بین دو کلاس و تعداد نقاط خطا افزایش می یابد.
روش C-SVM و روش v-SVM، با انتخاب مناسب پارامترها ممکن است به جواب یکسانی برسند.
ضرایب لاگرانژ پاسخ سیستم برای یک پایگاه داده خاص D، همواره منحصر به فرد است.
با افزودن داده آموزشی جدید به سیستم، همواره پاسخ سیستم تغییر می کند.
یک ماتریس کوواریانس کدام ویژگی ها از 5 ویژگی زیر را همیشه دارا است؟
a) وارون پذیری
b) قطری بودن
c) همه درایه ها مثبت هستند
d) متقارن بودن
e) داشتن حداقل یک مقدار ویژگی منفی
a و d
d
b، d و e
a، b، c و e
با افزایش پیچیدگی مدل، کدام مورد به ترتیب در خصوص بایاس و واریانس درست است؟
کاهش می یابد - افزایش می یابد
افزایش می یابد - کاهش می یابد
کاهش می یابد - ثابت می ماند
افزایش می یابد - ثابت می ماند
کدام طبقه بندی زیر نسبت به ترتیب ورود داده های آموزش حساس می باشد؟
درخت تصمیم
Hard SVM
طبقه بند K نزدیک ترین همسایه با K=15
شبکه عصبی پرسپترون
فرض کنید یک مجموعه دادگان متشکل از چندین کلاس مختلف، داده شده باشد و هر کلاس دارای توزیع احتمال متفاوتی باشد، اما برچسب کلاس هر داده موجود نباشد. اگر از روش خوشه بندی K-means برای تخمین برچسب کلاس هر داده استفاده شود، در کدام شرایط، کارآیی خوشه بندی افزایش می یابد؟
با میانگین های متفاوت، واریانس توزیع هر کلاس در همه راستاها کوچک باشد.
عدد K یعنی تعداد خوشه ها برابر با n یعنی تعداد داده ها انتخاب شود.
همه کلاس ها میانگین یکسانی داشته باشند.
پراکندگی بین کلاسی کوچک باشد.
کدام یک از راهبردهای زیر، کاهش مشکل بیش برازش (overfitting) در طبقه بند درخت تصمیم کمکی نمی کند؟
اطمینان از اینکه هر گره برگ، یک کلاس خالص (Pure class) است.
محدود کردن حداقل تعداد نمونه ها در هر گره برگ
محدود کردن حداکثر عمق درخت
هرس کردن
کدام یک از توابع فعالیت Sigmoid, tanh, hard tanh,Relu ممکن است دچار انفجار گرادیان شود؟

Sigmoid
Tanh
Relu
Hard tanh
در یک طبقه بندی کننده دو کلاس بیز با ویژگی x در بازه ، توزیع ویژگی در کلاس اول به صورت داده شده است. اگر مرز تصمیم گیری نقطه باشد، تسبت احتمال پیشین دو کلاس کدام است؟
در یک مسئله طبقه بندی دو کلاسی با دو ویژگی و ، توزیع داده های آموزشی دو کلاس به صورت بیضی در شکل های زیر، رسم شده است. با روش بدون سرپرست PCA می خواهیم بعد فصا را به یک کاهش دهیم. تصویر داده ها روی بردار ویژه متناظر با بزرگ ترین مقدار ویژه ماتریس کوواریانس کل داده ها، در کدام شکل بهتر جداپذیری دو کلاس را حفظ می کند؟
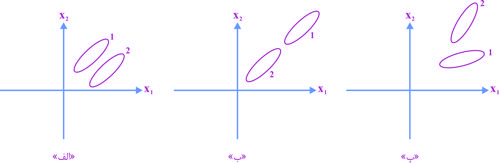
"الف"
"ب"
"پ"
در هر سه شکل، به یک اندازه جداپذیری دو کلاس حفظ می شود.
در یک مسئله طبقه بندی دو کلاسی در فضای 3 بعدی از هر کلاس 4 داده داریم و کل داده ها را در یک ماتریس قرار داده ایم. فرض می کنیم میانگین هر ویژگی روی 8 داده صفر است. فرض می کنیم بردارهای ویژه و مقادیر ویژه دو ماتریس، و به دست آمده اند. برای کاهش بعد فضا به یک با روش PCA، از کدام یک از بردارهای زیر استفاده می کنیم؟
بردار ویژه متناظر با کوچک ترین مقدار ویژه ماتریس
بردار ویژه متناظر با کوچکترین مقدار ویژه ماتریس
بردار ویژه متناظر با بزرگ ترین مقدار ویژه ماتریس
بردار ویژه متناظر با بزرگ ترین مقدار ویژه ماتریس
در فضای دوبعدی ویژگی، داده های دو کلاس با علامت O و X در شکل مشخص شده اند. اگر الگوریتم Hard SVM را روی این داده ها اجرا کنیم، کدام گزاره در مورد طبقه بندی طراحی شده در خصوص مرز تصمیم خطی درست است؟
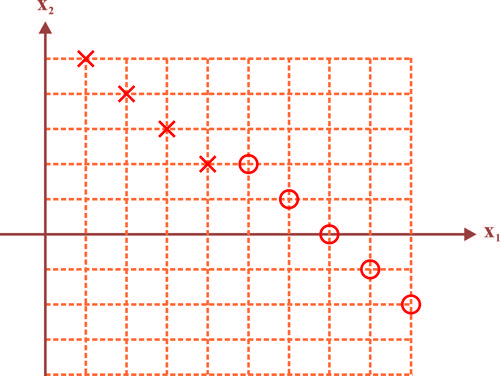
موازی با محور قائم است.
موازی با محور است.
موازی با محور است.
موازی محور افقی است.
در یک طبقه بندی کننده 3 کلاسی، از هر کلاس 100 داده تست داریم و بعد از آموزش طبقه بند، ماتریس Confusion داده های تست، به صورت آمده است. اگر دو کلاس 2 و 3 را باهم یک کلاس در نظر بگیریم و از روی ماتریس داده شده در زیر، یک ماتریس Confusion برای طبقه بندی دو کلاس بسازیم، درصد صحت Accuracy طبقه بندی دو کلاسی کدام است؟
برچسب واقعی | ||||
|---|---|---|---|---|
کلاس 3 | کلاس 2 | کلاس 1 | برچسب تعیین شده توسط طبقه بند | |
6 | 4 | 90 | کلاس 1 | |
2 | 91 | 3 | کلاس 2 | |
92 | 5 | 7 | کلاس 3 | |
در فضای دوبعدی ویژگی، 5 داده از هر یک از دو کلاس در یک مسئله طبقه بندی دوکلاسی در شکل داده شده است. اگر به روش Leave-one-out هر یک از داده ها را به عنوان داده تست در نظر بگیریم و به روش K-NN با k=1 برای آن برچسبی تخمین بزنیم، درصد صحت Accuracy چقدر خواهد شد؟
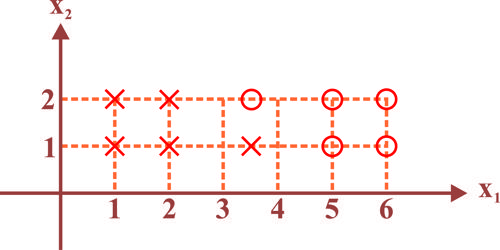
100
90
80
70