حل تشریحی سوالات مهندسی اطلاعات - کنکور دکتری مهندسی فناوری اطلاعات (IT) 1400
سوالات مهندسی اطلاعات
15 سوالپروتکل Go-Back-N با اندازه پنجره ۴، در یک ارتباط مورد استفاده قرار میگیرد. فرض کنید در لحظه t گیرنده منتظر دریافت بسته با شماره دنباله k است. کدام گزینه مجموعه محتمل برای شماره دنباله بستههای ارسالی در فرستنده نیست؟ (فرض کنید که هنگام انتقال ترتیب بسته ها به هم نمیریزد.)
در مورد پروتکل BGP کدام گزینه درست نیست؟
پیامهای BGP اطلاعات لازم را برای انتخاب کوتاه ترین مسیر فراهم میکنند.
پیام های BGP اطلاعات کامل برای اعمال سیاست گذاری های انتخاب مسیر را فراهم میکنند.
پیامهای BGP امکان تشخیص حلقه و دور ریختن مسیرهای با این ویژگی را فراهم میکنند.
در پیام های BGP، مسیر کامل به شکل لیست ASهای در مسیر برای رسیدن به مقصد آورده میشود.
در (Pretty Good Privacy (PGP برای امنیت ایمیل میتوان هم آن را رمز و هم امضا کرد. شکل زیر فرایند این کار را در یک ارسال ایمیل از a به نشان میدهد. در این شکل 2 نماد فشرده ساز و کلید متقارنی که با آن محتوای ایمیل رمز میشود و PR نماد کلید خصوصی و PU نماد کلید عمومی فرد نوعی x است. کدام گزینه در مورد دلیل قرار دادن اپراتور 2 پس از مرحله امضا و پیش از رمزنگاری نادرست است؟
بهتر است پیام امضا شده و سپس Z اعمال شود تا در صورتی که گیرنده خواست بتواند امضا را کنار پیام باز شده برای تصدیق آن در آینده ذخیره کند.
قرار دادن Z پس از امضا میتواند طول امضا را هم تا حد زیادی کاهش دهد، و این مقداری جبران افزایش طول ۳۳ درصدی را که تبدیل ۶۴- radix در ادامه تحمیل میکند خواهد کرد.
قرار دادن Z قبل از رمزنگاری باعث ایجاد امکان استفاده از افزونگیهای متن پیام برای کاهش حجم آن و تا حدى جبران افزایش طول ۳۳ درصدی که تبدیل ۶۴- radix در ادامه تحمیل می کند، میشود.
قرار دادن Z قبل از رمزنگاری امنیت را افزایش میدهد، چرا که متن فشرده شده افزونگی (redundancy) کمتری نسبت به متن فشرده نشده دارد و تحلیل خروجی رمز کننده برای یافتن پیام اصلی را سخت تر میکند.
یک برنامه کاربردی نرم افزار داریم که برای ارتباط امن با برنامه ای دیگر از یک رمز بلوکی (Block Cipher) کلید متقارن با طول بلوک (قالب) L استفاده میکرده است. طراح نرم افزار تصمیم گرفته است که در نسخه جدید آن به جای رمز متقارن از رمز کننده نامتقارن RSA استفاده کند. بدین شکل که ماجول رمزنگاری قبلی را برداشته و ماجول جدید را جایگزین آن کند بدون آنکه به جز بخش مدیریت کلید بخش دیگری از برنامه را دست بزند. اگر برای سادگی فرض کنیم L=8 بیت بوده باشد کدام گزینه تنظیمات قابل قبول برای جایگزینی را ارائه می دهد به نحوی که سطح امنیت کاهش نیافته و سیستم نیز کار کند؟ (فرض کنید p و q اعداد اول سازنده پیمانه n در RSA بوده و e کلید رمزنگاری آن است. پیام یا بلوک ارسالی را فرض کنید.)
p=19,q=17,e=35
p=13,q=23,e=55
p=13,q=17,e=5
از آنجا که در حالت کلی بزرگترین مقسوم علیه مشترک m و n همیشه یک نیست این جایگزینی الگوریتم رمز شدنی نیست.
در شبکهای با ۹ کاربر نیاز به ارتباط محرمانه بین هر دو کاربر داریم دو طرح برای ایمن سازی ارتباطات بین کاربران در این شبکه پیشنهاد شده است. طرح اول از رمزنگاری متقارن استفاده میکند و طرح دوم از رمزنگاری نامتقارن اختلاف تعداد کلیدهای رمزنگاری به کار رفته در این دو طرح کدام است؟
9
18
27
36
چه تعداد از گزارههای زیر درست است؟
- امضاهای دیجیتال از رمزنگاری نامتقارن برای احراز هویت استفاده میکنند.
- علت استفاده از توابع چکیده ساز همراه با امضای دیجیتال افزایش مقاومت در برابر حملات جعل امضا است.
- محاسبه چکیده یک پیام با استفاده از توابع چکیده ساز رمزی نظیر ۱-SHA، نیازمند آگاهی از کلید پنهان است.
- به هنگام محاسبه کد MAC استفاده از بردار مقداردهی اولیه (IV) تصادفی که توسط مهاجمین قابل حدس نباشد ضروری است.
1
2
3
4
کدام گزینه در مورد پروتکل TLS درست است؟
یکی از مشکلات جدی TLS این است که حتی پس از مشخص شدن این که کلید خصوصی سرور لو رفته است، مرورگر کلاینت راهی برای اطلاع از اینکه نباید گواهی سرور را معتبر بداند نخواهد داشت.
یک کلاینت TLS، اعتبار گواهی الکترونیکی که یک سرور برای او فرستاده است را با بررسی امضای دیجیتال سرور بر روی گواهی تعیین میکند.
TLS هم از رمزهای متقارن و هم رمزهای نامتقارن استفاده میکند.
TLS همیشه هویت کلاینت را برای سرور احراز میکند.
در سطوح جدایی در استاندارد SQL کدام مورد درست است؟
در سطح جدایی Serializable ممکن است مشکل شبح داده و خواندن داده ناجور رخ دهد.
در سطح جدایی Read committed ممکن است مشکل شبح داده و خواندن داده ناجور رخ دهد.
در سطح جدایی Repeatable read ممکن است مشکل شبح داده و خواندن تکرار نشدنی رخ دهد.
در سطح جدایی Read committed ممکن است مشکل شبح داده و خواندن تکرار نشدنی رخ دهد.
در طرح زیر، lock point در تراکنشهای T1 و T2 در چه زمانی اتفاق میافتد؟

Lock point در T1 و T2 بهترتیب در لحظه ۲ و ۴ اتفاق میافتد.
Lock point در T1 و T2 بهترتیب در لحظه 5 و 6 اتفاق میافتد.
Lock point در T1 و T2 بهترتیب در لحظه 5 و 7 اتفاق میافتد.
Lock point در T1 و T2 بهترتیب در لحظه 5 و 10 اتفاق میافتد.
طرح زیر کدام یک از مشکلات تداخل کنترل نشده را میتواند داشته باشد؟
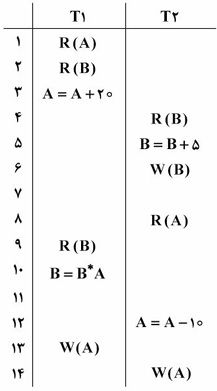
تحلیل ناسازگار - خواندن داده ناجور - خواندن تکرار نشدنی
تحلیل ناسازگار - بهنگام سازی از دست رفته - خواندن داده ناجور
تحلیل ناسازگار - بهنگام سازی از دست رفته - خواندن تکرار نشدنی
هیچکدام
چه تعداد از جملات زیر درست است؟
(A) وظیفه حفظ سازگاری (Consistency) یک تراکنش مجزا (Individual Transaction) بر عهده سیستم مدیریت پایگاه داده است.
(B) سیستم بازیابی (Recovery System) پایگاه داده فقط وظیفه حفظ مانایی (Durability) تراکنش ها را از مجموعه ویژگیهای ACID تراکنش ها بر عهده دارد.
(C) اعمال Compensating و Roll Back در تراکنش ها معادل همدیگر نیستند و با یکدیگر تفاوت دارند.
(D) همواره دو زمان بندی (Schedule) که خروجی یکسان تولید می کنند Conflict equivalent یکدیگر
هستند.
(E) حتی با اضافه کردن ویژگی Time Out به طرح Wait-die باز هم امکان ندارد تراکنشی در این طرح دچار گرسنگی (Starvation) شود.
1
2
3
4
بر اساس روش بازیابی ARIES، شماره RedoLSN مربوط به Log داده شده کدام است؟ (RedoLSN شماره لاگی است که عمل Redo باید از آنجا شروع شود.

۷۵۶۹
۷۵۶۷
۷۵۶۴
۷۵۶۲
در یک فضای جستجو دو سند و داریم متن این دو سند به صورت زیر است: (حروف A تا F کلمات هستند)
فرض کنید یک پرس وجو به صورت EB داریم و می خواهیم با استفاده از مدل زبانی query likelihood احتمال این دو سند را با دو روش unigram و bigram محاسبه کنیم در صورت استفاده از روش unigram هیچ هموارسازی ای انجام نمیشود و در صورت استفاده از روش bigram هموارسازی به مدل unigram با استفاده از روش Linear Interpolation با انجام میشود. کدام گزینه صحیح است؟
برای هر دو روش unigram و bigram سند احتمال بیشتری دارد.
برای هر دو روش unigram و bigram سند احتمال بیشتری دارد.
برای روش unigram سند و برای روش bigram، سند احتمال بیشتری دارد.
برای روش unigram سند و برای روش bigram سند احتمال بیشتری دارد.
با در نظر گرفتن این که بسامد تکرار کلمه در سند (Term Frequency)، بسامد تکرار کلمه در کل اسناد (Document Frequency) و طول سند (Document length) اطلاعات کلیدی در بازیابی اسناد هستند مشخص کنید در روشهای Language Model Vector Space model و BM25 کدام یک از اطلاعات فوق لحاظ شده است؟
در Vector Space و BM25 هر سه اطلاعات لحاظ شده اما در Language Model بسامد تکرار کلمه در
کل اسناد لحاظ نشده است.
در B25 و Language Model هر سه اطلاعات لحاظ شده اما در Vector Space طول سند لحاظ نشده است.
در Vector Space و Language Model هر سه اطلاعات لحاظ شده اما در BM25 طول سند لحاظ نشده است.
در هر سه روش هر سه اطلاعات لحاظ شده
کدام عبارت (عبارات) صحیح هستند؟
(توضیح: P@k یا Precision at k does دقت در سند اول است.
P@k یا Recall at k does فراخوانی در سند اول است.)
الف) برای یک لیست مرتب از نتایج P@5 می تواند کمتر از P@10 باشد.
ب) برای یک لیست مرتب از نتایج R@5 می تواند کمتر از R@10 باشد.
ج) پرس و جویی را در نظر بگیرید که 10 سند مرتبط با آن در مجموعه اسناد وجود دارد. برای یک لیست مرتب از نتایج در پاسخ به این پرس وجو، P@5 می تواند کمتر از R@5 باشد.
الف
ب
الف و ب
الف و ب و ج